
逻辑回归(Logistic Regression)是机器学习中用于解决二分类或多分类问题的经典算法。虽然名称中包含”回归”,但它实际上是一种分类算法,特别适用于预测概率输出。
逻辑回归基础概念
想象一下线性回归:y = wx + b。它输出一个连续的、可以是任意大小的数值。如果我们想用它来预测一个类别(例如:0 或 1,是或否),直接使用它的输出是不合适的。
因此,我们要想办法找一个函数,将线性回归的结果映射到一个介于 0 和 1 之间的值,这里记作 p。当 p>0.5 时判定为 1,反之判定为 0。如此一来,就可以实现训练模型-输入数据-获得分类结果。
通常情况下,逻辑回归是一个线性模型,当然,也可以调整成非线性的,本文只讨论线性模型的情况,且直接讨论通用形式,不对二维情形做单独的讨论。
逻辑回归数学原理
Sigmoid 函数
sigmoid 函数的公式如下:
$$\sigma (z) = \frac{1}{{1 + {e^{ – z}}}}$$
它的图像是一个优美的”S”型曲线:
- 当$z \to + \infty $时,输出$\sigma (z)$ 无限接近 1。
- 当$z \to – \infty $时,输出$\sigma (z)$ 无限接近 0。
- 当$ z=0 $时,$\sigma (z) = 0.5$
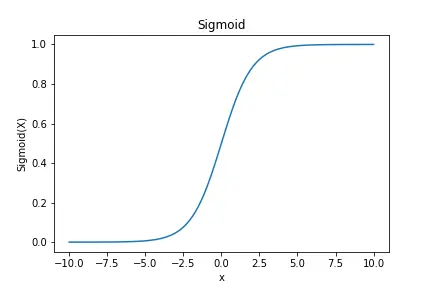
这个特性完美地将任何实数转换成了(0,1)区间的值,我们可以将其解释为概率。
逻辑回归模型
在逻辑回归中,我们将线性回归的输出 $z = {\omega _0} + {\omega _1}{x_1} + {\omega _2}{x_2} + \cdots + {\omega _n}{x_n}$作为 Sigmoid 函数的输入。
令${\underline \omega ^T} = \left[ {{\omega _0},{\omega _1},{\omega _2}, \cdots ,{\omega _n}} \right]$,$\underline x = \left[ {1,{x_0},{x_1}, \cdots ,{x_n}} \right]$,则$z = {\underline \omega ^T}\underline x $
之后,将 z 代入 Sigmoid 函数,得到预测概率
$$\hat y = P\left( {\left. {y = 1} \right|\underline x } \right) = \frac{1}{{1 + {e^{ – \left( {{{\underline \omega }^T}\underline x } \right)}}}}$$
决策边界
我们得到了一个概率,如何最终做出分类决策呢?我们需要设定一个阈值,通常默认为 0.5:
- $\hat y \ge 0.5$,预测为 1
- $\hat y < 0.5$,预测为 0
由于 Sigmoid 函数在 $ z=0 $时输出 0.5,所以这个决策规则等价于:
- ${\underline \omega ^T}\underline x \ge 0$,预测为 1
- ${\underline \omega ^T}\underline x < 0$,预测为 0
这个${\underline \omega ^T}\underline x $就是一个决策边界,在二维空间中是一条直线,在三维空间中是一个平面,在高维空间中是一个超平面。逻辑回归的本质就是通过学习参数$\underline \omega $来找到这个最佳决策边界。
损失函数
模型需要学习,就必须有一个衡量预测好坏的指标,这就是损失函数。线性回归用的是均方误差,但它在逻辑回归中不是一个好的选择(会导致非凸优化问题,容易陷入局部最优)。
逻辑回归使用 交叉熵损失函数。
对于单个样本,其损失函数定义为:
$$L\left( {\hat y,y} \right) = – \left[ {y\log \left( {\hat y} \right) + \left( {1 – y} \right)\log \left( {1 – \hat y} \right)} \right]$$
- 当真实标$y=1$ 时,损失函数变为$- {\log \left( {\hat y} \right)}$。如果预测概率${\hat y}$越接近 1,损失 越$- {\log \left( {\hat y} \right)}$接近 0(预测正确);如果 ${\hat y}$ 越接近 0,损失 $- {\log \left( {\hat y} \right)}$会变得非常大(惩罚预测错误)。
- 当真实标签 $y=0$ 时,损失函数变为 ${-\log \left( {1 – \hat y} \right)}$。如果预测概率$ \hat y$ 越接近 0,损失越接近 0;如果$ \hat y$ 越接近 1,损失会变得非常大。
代价函数
定义平均交叉熵损失(代价函数):
$$J(w,b)=\frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})$$
其中$L(\hat{y}^{(i)},y^{(i)})=-[y^{(i)}\log(\hat{y}^{(i)})+(1-y^{(i)})\log(1-\hat{y}^{(i)})]$是单个样本的损失,$\hat{y}^{(i)}=\sigma(z^{(i)})=\frac{1}{1+e^{-z^{(i)}}}$是模型的预测输出。
参数学习:梯度下降法
我们的目标是找到$\underline \omega ^T$,使得总的代价函数(平均交叉熵损失)最小化。
这个过程通常通过梯度下降算法来实现。其核心思想是:
- 初始化参数 $\underline \omega ^T$
- 计算代价函数对每个参数的梯度(偏导数)。
- 沿着梯度的反方向(即下降最快的方向)更新参数。
- 重复步骤 2 和 3,直到代价函数收敛或达到预设的迭代次数。
参数更新公式如下:
$$w_j:=w_j-\alpha\frac{\partial J(\mathbf{w},b)}{\partial w_j}$$
其中 $\alpha$是学习率,控制每次更新的步长。
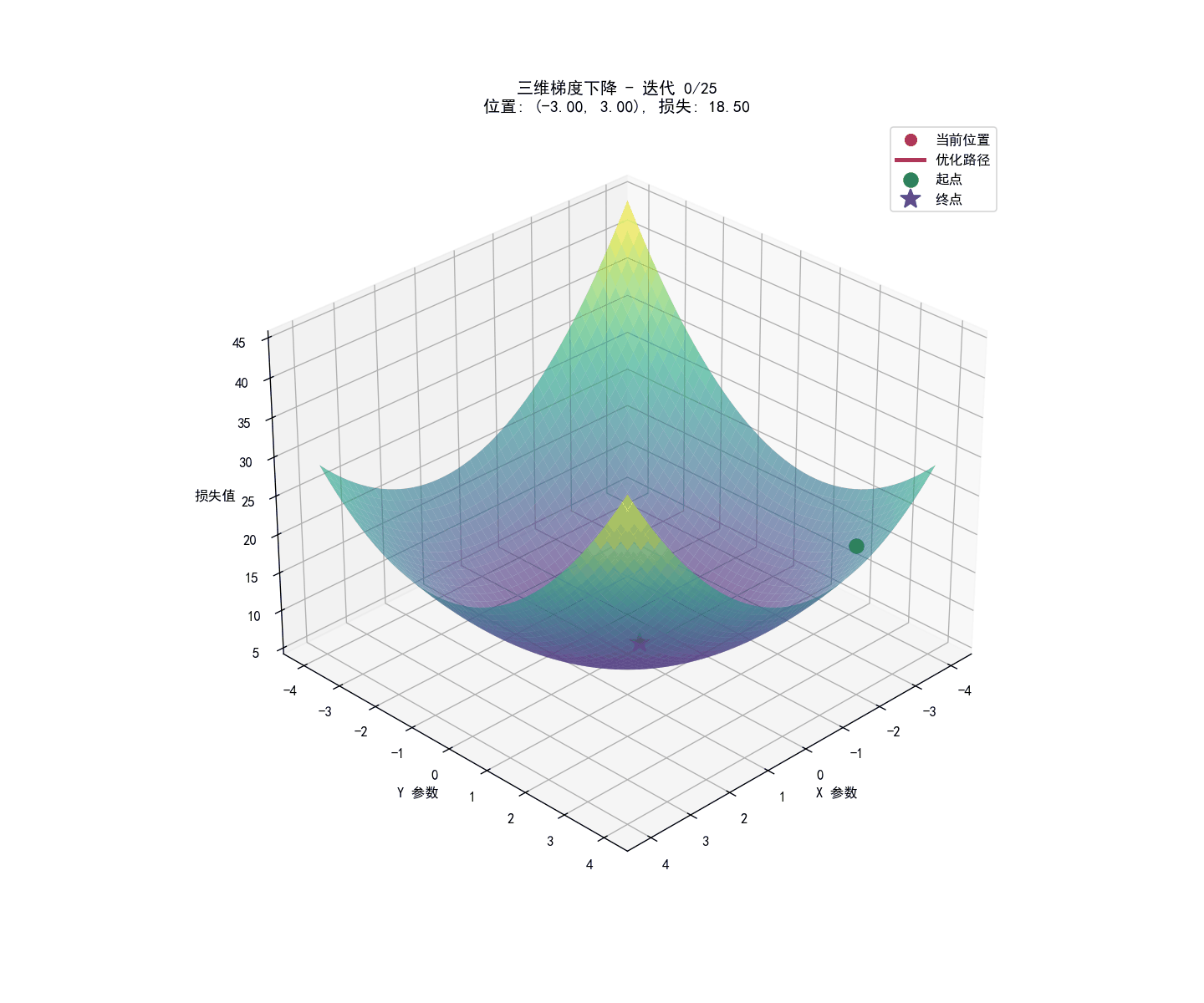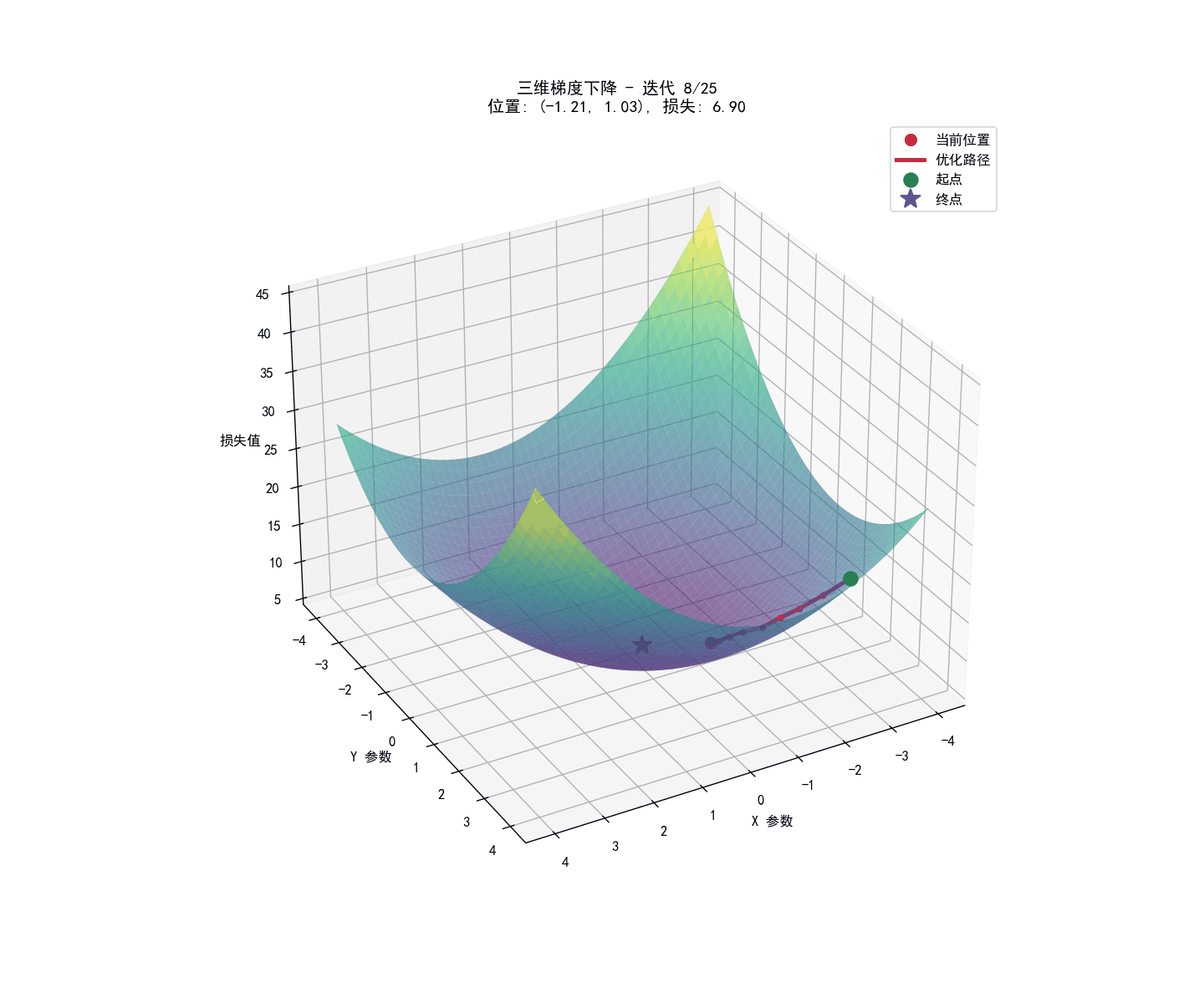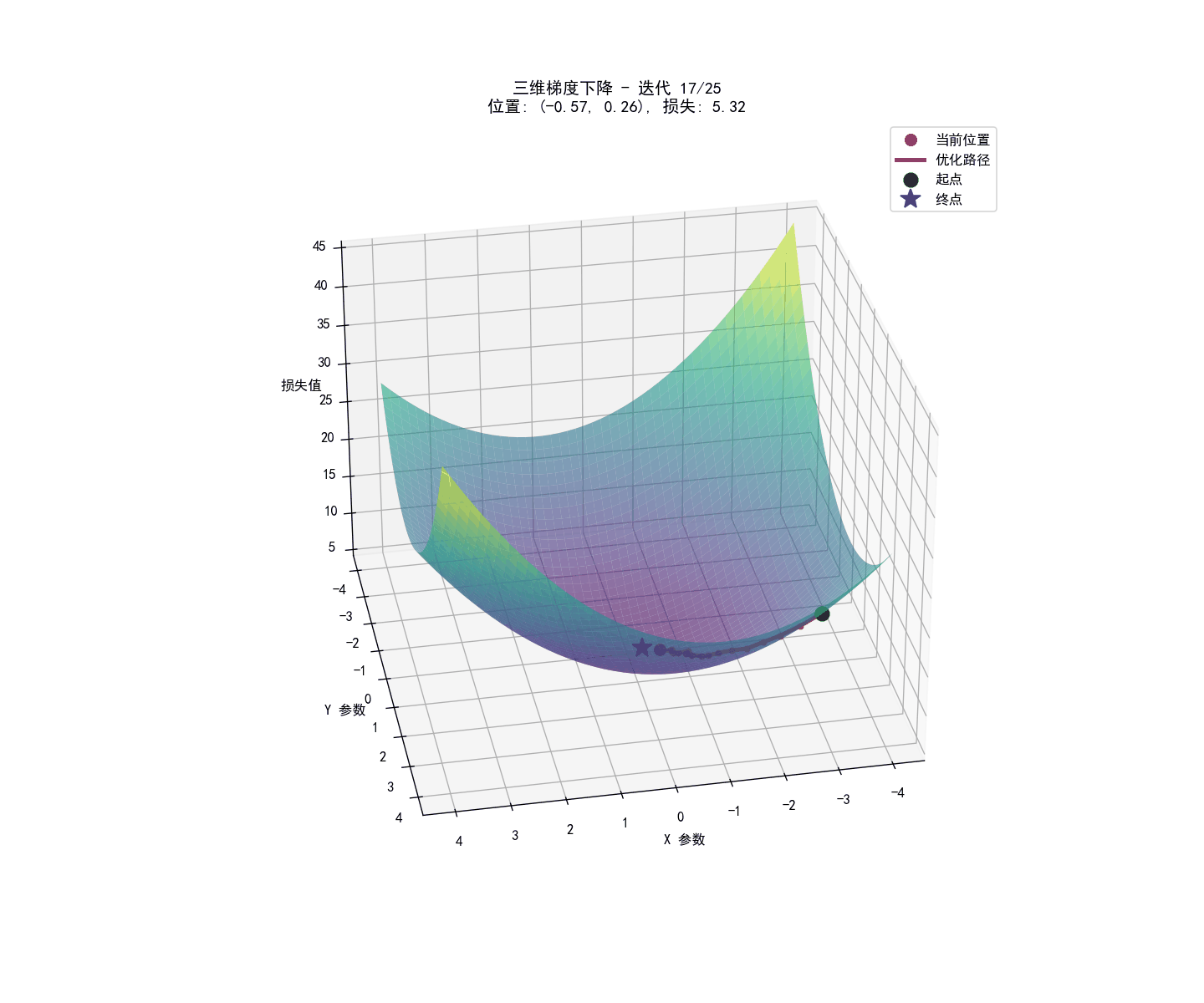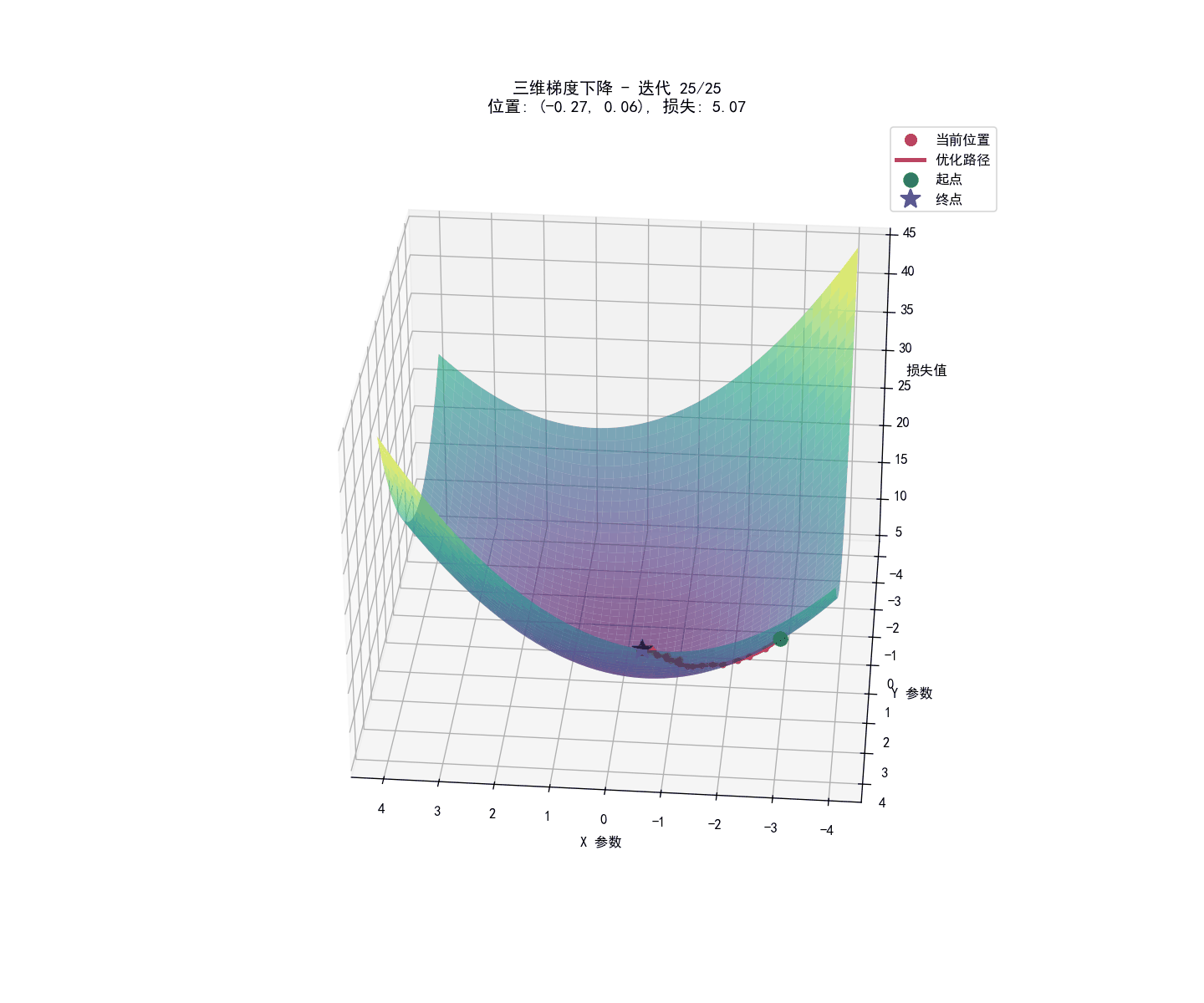
逻辑回归矩阵运算实现
矩阵运算一般情形
假设有 $m$ 个样本,每个样本有 $n$ 个特征变量 $x_1, x_2, \dots, x_n$,加上偏置项 $x_0 = 1$。
矩阵定义
特征矩阵 $X$:维度 $m \times (n+1)$
$$X = \begin{bmatrix} 1 & x_{1,1} & x_{1,2} & \dots & x_{1,n} \\ 1 & x_{2,1} & x_{2,2} & \dots & x_{2,n} \\ \vdots & \vdots & \vdots & & \vdots \\ 1 & x_{m,1} & x_{m,2} & \dots & x_{m,n} \end{bmatrix}$$
参数向量 $\theta$:维度 $(n+1) \times 1$
$$\theta = \begin{bmatrix} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_n \end{bmatrix}$$
标签向量 $y$:维度 $m \times 1$
$$y = \begin{bmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(m)} \end{bmatrix}, \quad y^{(i)} \in \{0,1\}$$
假设函数
对每个样本的预测:
$$h_\theta(x^{(i)}) = \sigma(x^{(i)} \theta) = \frac{1}{1 + e^{-x^{(i)} \theta}}$$
向量化(对整个数据集):
$$z = X \theta \quad (m \times 1)$$
$$h = \sigma(z) = \frac{1}{1 + e^{-z}} \quad \text{(逐元素运算)}$$
这里 $h$ 是 $m \times 1$ 向量,表示每个样本的预测概率 $P(y=1|x;\theta)$。
代价函数
$$J(\theta) = -\frac{1}{m} \left[ y^T \log(h) + (1 – y)^T \log(1 – h) \right] + \frac{\lambda}{2m} \theta_{1:n}^T \theta_{1:n}$$
其中 $\log(\cdot)$ 逐元素取自然对数,$\theta_{1:n}$ 表示去掉 $\theta_0$ 的 $n \times 1$ 向量,$\lambda$ 是正则化参数。
梯度下降迭代
梯度:
$$\frac{\partial J}{\partial \theta} = \frac{1}{m} X^T (h – y) + \frac{\lambda}{m} \begin{bmatrix} 0 \\ \theta_1 \\ \vdots \\ \theta_n \end{bmatrix}$$
迭代更新:
$$\theta := \theta – \alpha \frac{\partial J}{\partial \theta}$$
其中 $\alpha$ 是学习率。
展开写:
$$\theta := \theta – \alpha \left[ \frac{1}{m} X^T (h – y) + \frac{\lambda}{m} \begin{bmatrix} 0 \\ \theta_1 \\ \vdots \\ \theta_n \end{bmatrix} \right]$$
迭代过程算法步骤
- 初始化 $\theta = \mathbf{0}_{(n+1)\times 1}$
- 重复直到收敛:
- 计算 $z = X \theta$ ($m \times 1$)
- 计算 $h = \sigma(z) = 1 ./ (1 + \exp(-z))$ (逐元素,$m \times 1$)
- 计算误差 $\text{error} = h – y$ ($m \times 1$)
- 计算梯度: $$\text{grad} = \frac{1}{m} X^T \cdot \text{error}$$ 如果正则化: $$\text{grad} = \text{grad} + \frac{\lambda}{m} \begin{bmatrix} 0 \\ \theta_1 \\ \vdots \\ \theta_n \end{bmatrix}$$
- 更新参数: $$\theta := \theta – \alpha \cdot \text{grad}$$
- 检查收敛条件
矩阵维度小结
- $X$: $m \times (n+1)$
- $\theta$: $(n+1) \times 1$
- $y$: $m \times 1$
- $z = X\theta$: $m \times 1$
- $h = \sigma(z)$: $m \times 1$
- $X^T(h-y)$: $(n+1) \times 1$
逻辑回归 Python 实现
具体案例分析
假设我们需要根据学生的两项成绩,来判断他们是否通过期末考核。目前我们手上有三个学生的历史数据,将其转化为特征矩阵 :
$$X=\begin{bmatrix} 1 & 85 & 78 \\ 1 & 62 & 65 \\ 1 & 92 & 88 \end{bmatrix}$$
- 第 1 列:偏置项(始终为 1)
- 第 2 列:数学成绩(满分 100)
- 第 3 列:英语成绩(满分 100)
标签向量 y(1=通过,0=未通过):
$$y = {\left[ {1,0,1} \right]^T}$$
初始参数:
$$w=\begin{bmatrix} w_0 \\ w_1 \\ w_2 \end{bmatrix}=\begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}$$
且令$\alpha=0.2$。
以第一次迭代过程为例:
- 计算线性输出 $z$: $$z = Xw = \begin{bmatrix} 1 & 85 & 78 \\ 1 & 62 & 65 \\ 1 & 92 & 88 \end{bmatrix} \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}$$
- 计算预测概率 $\hat{y}$(Sigmoid 函数): $$\hat{y} = \sigma(z) = \frac{1}{1 + e^{-z}} = \begin{bmatrix} \sigma(0) \\ \sigma(0) \\ \sigma(0) \end{bmatrix} = \begin{bmatrix} 0.5 \\ 0.5 \\ 0.5 \end{bmatrix}$$
- 计算预测误差: $$\hat{y} – y = \begin{bmatrix} 0.5 \\ 0.5 \\ 0.5 \end{bmatrix} – \begin{bmatrix} 1 \\ 0 \\ 1 \end{bmatrix} = \begin{bmatrix} -0.5 \\ 0.5 \\ -0.5 \end{bmatrix}$$ 计算梯度 $\nabla_w J$: $$\nabla_w J = \frac{1}{3} \begin{bmatrix} 1 & 1 & 1 \\ 85 & 62 & 92 \\ 78 & 65 & 88 \end{bmatrix} \begin{bmatrix} -0.5 \\ 0.5 \\ -0.5 \end{bmatrix} = \frac{1}{3} \begin{bmatrix} -0.5 \\ -37.5 \\ -30.5 \end{bmatrix} = \begin{bmatrix} -0.1667 \\ -12.5 \\ -10.1667 \end{bmatrix}$$
- 更新参数 $w$: $$w := w – \alpha \nabla_w J = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix} – 0.1 \times \begin{bmatrix} -0.1667 \\ -12.5 \\ -10.1667 \end{bmatrix} = \begin{bmatrix} 0.01667 \\ 1.25 \\ 1.01667 \end{bmatrix}$$
之后周而复始,就可以逐渐逼近最佳参数了。
Python 代码实现
import numpy as np
# 逻辑回归梯度下降实现
class LogisticRegression:
def __init__(self, learning_rate=0.1, max_iters=1000, tol=1e-4):
self.learning_rate = learning_rate
self.max_iters = max_iters
self.tol = tol
self.w = None
self.loss_history = []
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def compute_loss(self, y_true, y_pred):
# 交叉熵损失
return -np.mean(y_true * np.log(y_pred + 1e-8) + (1 - y_true) * np.log(1 - y_pred + 1e-8))
def fit(self, X, y):
# 添加偏置项
X = np.column_stack([np.ones(X.shape[0]), X])
# 初始化参数
self.w = np.zeros(X.shape[1])
m = len(y)
print("开始训练...")
print(f"初始参数: w = {self.w}")
print(f"学习率: {self.learning_rate}")
print("-" * 50)
for i in range(self.max_iters):
# 前向传播
z = X @ self.w
y_pred = self.sigmoid(z)
# 计算损失
loss = self.compute_loss(y, y_pred)
self.loss_history.append(loss)
# 计算梯度
gradient = (1/m) * X.T @ (y_pred - y)
# 更新参数
w_prev = self.w.copy()
self.w -= self.learning_rate * gradient
# 打印迭代信息
if i < 3 or i % 100 == 0:
print(f"迭代 {i+1}:")
print(f" 预测值: {y_pred.round(4)}")
print(f" 损失: {loss:.6f}")
print(f" 梯度: {gradient.round(6)}")
print(f" 参数: w = {self.w.round(6)}")
print("-" * 30)
# 检查收敛
if np.linalg.norm(self.w - w_prev) < self.tol:
print(f"在第 {i+1} 次迭代收敛")
break
return self
def predict_proba(self, X):
X = np.column_stack([np.ones(X.shape[0]), X])
return self.sigmoid(X @ self.w)
def predict(self, X, threshold=0.5):
return (self.predict_proba(X) >= threshold).astype(int)
# 示例数据
X = np.array([
[85, 78], # 学生 1: 数学 85, 英语 78 → 通过
[62, 65], # 学生 2: 数学 62, 英语 65 → 未通过
[92, 88] # 学生 3: 数学 92, 英语 88 → 通过
])
y = np.array([1, 0, 1])
# 创建并训练模型
model = LogisticRegression(learning_rate=0.1, max_iters=1000)
model.fit(X, y)
# 预测
print("\n=== 预测结果 ===")
y_pred_proba = model.predict_proba(X)
y_pred = model.predict(X)
for i in range(len(X)):
print(f"学生{i+1}: 数学{X[i,0]}, 英语{X[i,1]} → "
f"预测概率: {y_pred_proba[i]:.4f} → "
f"预测类别: {y_pred[i]} (真实: {y[i]})")
print(f"\n 最终参数: w0 = {model.w[0]:.6f}, w1 = {model.w[1]:.6f}, w2 = {model.w[2]:.6f}")