
前言
想写这篇文章已经很久了。
2022年11月30日,是一个改变历史进程的日子。在这天,OpenAI 发布了 chatgpt-3.5 系列大模型,是全球首个较为智能的,可以进行多轮对话的大语言模型。模型发布后迅速在全球走红,资本开始抱团进入。
当时的版本以现在的角度看来,是有些“笨拙”的:回复套路化,准确度也不佳。社会争论的点还停留在是否要限制ai的发展、ai是否会毁灭人类等等。
总体上看,ai对整个社会的影响是颠覆性的,加速了发展进程。但从另一种角度看,ai正在摧毁我们的生活。
时间线回顾
2022年底,chatgpt爆火之后,国内外都进入了一个奇怪的真空期。
2023年
在国外,其他资本反应迅速,谷歌等科技巨头相继入场。国内的情形也差不太多,百度和腾讯以及阿里都投入研发。当时国内能用上 chatgpt 的人少之又少,大部分人都在用百度的 文心一言。文心一言的智能程度很低,只能回答一些基础的问题,但有总比没有好。
当时大部分人对ai持有的都是中立的态度,网络上反对chatgpt的声音还是很大,认为影响公平,以及会让人变得懒惰。
国内高校在2023年普遍开始建立人工智能学院,大部分是从计算机学院中独立出来的。当时是一个很关键的窗口期,敢选进去的学生,现在基本都走在研究前列。
2023年8月是一个转折点。抖音母公司推出了 豆包 大模型,智能程度相比于文心一言有质的飞跃。抖音通过其强大的推流能力,在国内铺开市场。
2024年
社会对ai的接受程度大幅提高,国内外都出台了相关的政策,对ai的发展进行规范化管理
谷歌推出 Gemini 2.0 模型,和gpt同台竞技。在这里不得不感慨一下,有钱就是好,一年烧几百亿刀,直接把差距追平。
国内外高校都有些矫枉过正,严禁学生在作业中使用ai
这一年,国外的模型都在走全模态道路,即文字、图片、语音三合一。
2025年
2025年1月10日,另一个重要的时间节点。深度求索发布了 deepseek-r1 模型。这是世界上首个有深度思考功能的ai大模型,且Moe构架使其训练成本比其他大模型少了几百倍。deepseek刚发布时,全球都在质疑其训练成本是否造假。发布一周后,英伟达股票暴跌17%,市值蒸发4.3万亿元。虽然后来又涨回去了,但现在看来仍然令人震惊。
deepseek对国内各界来说都是强心剂。资本市场终于认清了ai是未来的大方向,开始投入更多资金;政府把deepseek当成典范在全国范围内推行,几乎每个单位都进行了相关的使用培训。更重要的是,我们有自己的大模型可以用了,deepseek用起来确实能够媲美chatgpt,在国内遥遥领先。
在2025年的前半年,全国人民都处于新鲜状态中;后半年开始,ai已然进入了日常生活中,不再被视为一种新鲜事物。
同年,国外的进展更为迅猛。chatgpt 更新到第五代;谷歌发布Gemini 3.0pro ,是全球最强综合ai;马斯克发布grok 模型,在降低幻觉率和网络搜索方面断档领先;还有著名的claude 系列模型,编程特别厉害。
高校学生普遍使用ai。不用ai会导致效率不如别人,且跟不上教学进度。此外,markdown的使用率爆炸式增长,因为word是闭源的,ai没法创建word,而语言大模型的输出原生就是markdown格式,只需要直接复制粘贴就可以呈现。
在这一年,国内外ai的发展出现显著区别。国外ai都是付费模式,需要开会员才能拥有相对高的使用额度;国内都是免费+付费模式,使用网页或app聊天免费,使用api调用收费。说实话,国内免费是对的,符合国情。国外收费模式更像是一种门槛,防止被滥用导致算力不足,因为订阅计划带来的收入远远无法覆盖模型的训练和运行成本。
同年,阿里云的 Qwen 系列模型大放异彩,是全球最大最好的开源模型,衍生出各种系列。其年末发布的 Qwen3-max ,非思考模式已经全面超过了deepseek。但阿里云并没有抢占大众市场,没有像deepseek这样全国推广,让大家免费使用。qwen模型只能通过api调用,如果想要网页聊天也可以,但非常麻烦,几乎没人用。
我们可以不加证明地认为,2025年是ai史上最重要的一年。国内外的模型有了前所未有的进步,智能程度已经可以媲美人类。且国内外的研究方向出现了很大的区别:国外走全模态道路,国内走纯文字模型道路。这其实是资本多少决定的。全模态的成本太高,国内大厂玩不起。光是一个谷歌现在一年在ai上面烧一千多亿美元。
2026年
2026的1月份和2月份,各大厂商都疯了。为了抢占市场,腾讯和阿里纷纷推出红包计划,只要下载对应的app,几乎人手白嫖一杯奶茶。
有趣的是,微信在腾讯元宝的活动快结束时,宣布ban掉此类推广链接,以此阻击阿里后续的推广
网络数据污染
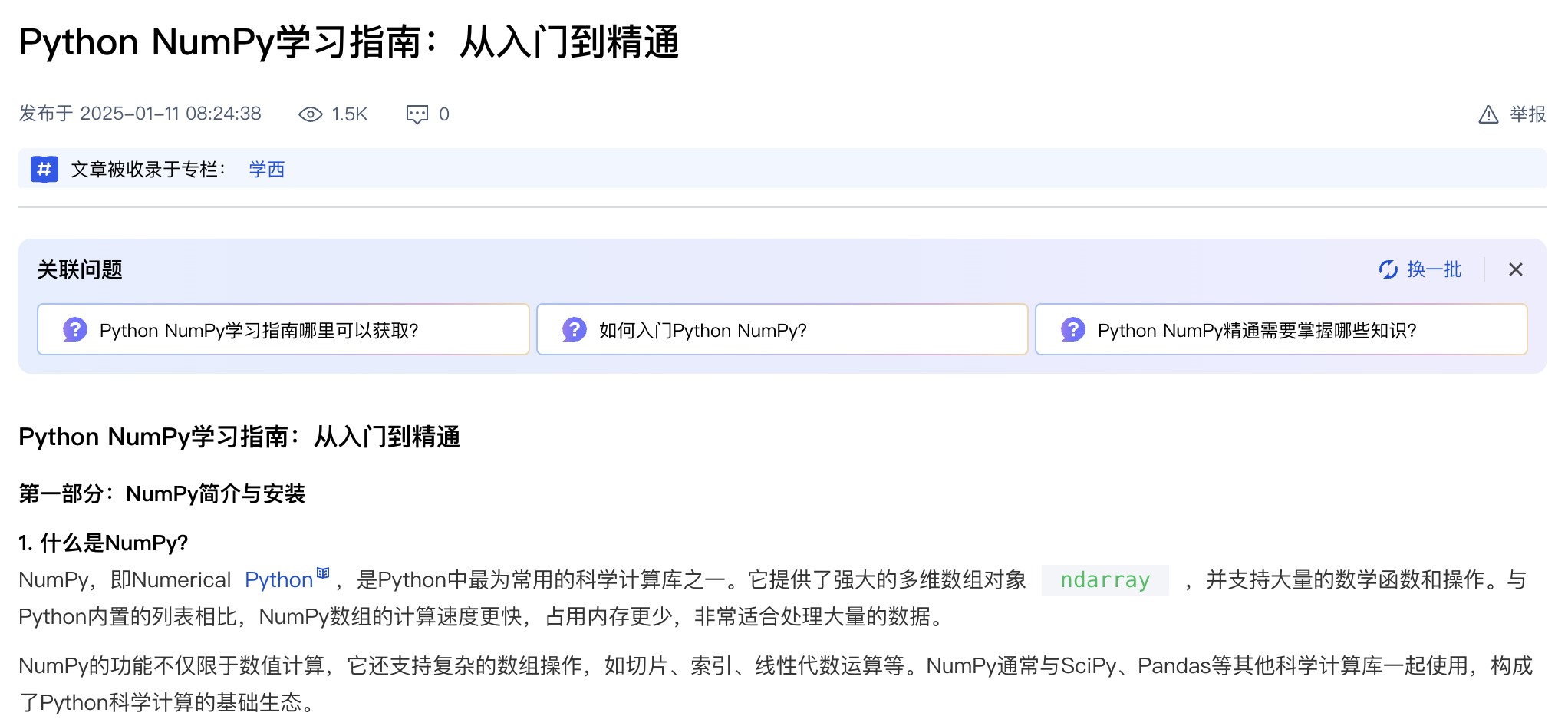
随着ai不断发展,很多低质量站点如雨后春笋般破土而出。他们的特点很明显:ai生成全文,并且优化成seo友好的形式,标题假大空,大多带有 完全指南 ,一站式 ,快速入门 等字眼。一点进去,浓浓的ai味铺面而来,什么概念引入,横向对比,没用的东西一大堆。真到了关键部分,代码甚至不能运行。
下面举一个例子,比如我想学习python 中的numpy 库:

会搜到两种类型的文章。
- 第一种是人写的,点进去发现结构清晰,语言简练:


- 第二种是ai写的,浪费时间且有误导性:

上面只是简单的例子,影响的也只是个人的搜索体验。
但问题又来了,ai的数据大部分取自网络。第一代ai用的都是原始的,真实的训练数据,但从第二代开始,就会接触到一些ai生成的数据。按照目前的趋势,迟早有一天,ai的训练数据全是ai生成的,效果会越来越差,幻觉率和错误率越来越高。
思考能力下降
记得我上高中的时候,ai还没有兴起。当时想学习一个数学的技巧,就需要去网上搜,搜到的都是各个博主认真制作的教学,附带他们的思考过程以及有例题的结合。但现在我大多数情况下不愿意再去网络上搜了,一是上面所说的数据污染问题,二是问ai真的很方便。比如我有一个代码不懂,去网络上搜,出来的全是ai生成的文章,效果还不如我直接问ai,让他给出简要的回答。
但长期使用ai带来的问题也很严重:
- 思考变得线性,习惯于罗列而非理解整体。比如我现在就直接敲了个1234的列表,不想花时间写成一段文字;
- 思考变得模块化,不再有清晰的主线。还是以这篇文章为例,用多级标题分割,没有清晰的主旨;
- 自身变成大号ai。和大模型对话久了,有时候惊觉自己的思考过程和
deepseek如出一辙
还有一个更严重的我想单独提一下,就是对于“拥有知识”认知的错位。在过去,“拥有知识”意味着完全掌握,熟料运用,但有了ai之后我常常会看个框架,然后把对话导出为文档,认为需要的时候查阅一下就行;有时候更懒,直接告诉自己这个东西要用时问一问ai就好。这是最可怕的,人不再拥有对知识的渴望。
离ai远一些
ai刚兴起时,许多人认为ai会替代大量岗位。事实上,这些岗位的工作人员只是转换了工作模式,更多的去调用ai解决问题。但问题也确实存在,首先是职业门槛降低。对于中低端信息行业,很多工作不再需要掌握大量的相关知识,只需要了解个大概,然后调用ai即可,这导致行业变卷。其次是劣币驱逐良币问题,很多时候,真正拥有技术的人在短期考核拼不过熟练运用ai的人,主管只看账面上的数据,不在意背后的隐形价值。
目前的趋势尚不明显,但是我相信在未来,知识才是最宝贵的财富。不依赖ai,认真掌握每一个细节的人才能笑到最后;当技术跑的太快时,我们需要留有一些人性。